To be completed!
Ch2: Preliminaries (預備知識)
Colab: ch2-2 (The output of all programs will be displayed on colab.)
講義地址: Heptabase 首頁
參考書籍: Dive into deep learning
上課日期: 2024/3/12, w4
# Linear Algebra
Essential in deep learning and AI.
- Scalars (純量)
- 標記:小寫 (x)
- 基本運算如下:
# Creating two PyTorch tensors 'x' and 'y'x = torch.tensor(3.0)
y = torch.tensor(2.0)
# Performing basic arithmetic operations using PyTorch tensors.# 'x + y' adds the two tensors.# 'x * y' multiplies the two tensors.# 'x / y' divides tensor 'x' by tensor 'y'.# 'x**y' raises tensor 'x' to the power of tensor 'y'.x + y, x * y, x / y, x**y
- Vector
- 標記:小寫粗體 ()
- Each element often represents a dataset feature.
- 基本運算如下:
x = torch.arange(3)
print(x)
# 'len(x)' returns the size of the first dimension of 'x', which is 3 in this case.print(len(x))
# 'x.shape' returns the dimensions of 'x', which is (3,) indicating it's a 1-dimensional tensor with 3 elements.print(x.shape)
- Matrices
- 標記:大寫粗體 ()
- 基本運算如下:
A = torch.arange(6).reshape(3, 2)
A, A.T # transpose (轉置)
- Tensors (張量)
- Definition: 推廣到更高維度的 n 維 arrays.
- 標記:特殊字體的大寫字母 (e.g., ).
- Applications: Images (3rd-order: 長寬和顏色), videos (4th-order), data batches.
torch.arange(24).reshape(2, 3, 4)
- Reduction (降維)
- Summation: Over vector, matrix, specific axes.
- Mean: Calculating average, along specific axes.
x = torch.arange(3, dtype=torch.float32)
A = torch.arange(6, dtype=torch.float32).reshape(2, 3)
x.sum(), A.mean()
- Non-Reduction Sum
sumwithkeepdims=True,用來保持張量的維度。- Broadcasting: Allows for operations on tensors of different shapes.
- Cumulative Sum (
cumsum): Calculates cumulative sum along a specified axis.
A = torch.arange(6).reshape(3, 2)
# Calculating the sum of elements in 'A' along axis 0 (column-wise sum) and keeping the same number of dimensions.# 'A.sum(axis=0, keepdims=True)' sums up elements column-wise and 'keepdims=True' retains the 2D shape of the result.# This will result in a 1x2 tensor.sum_result = A.sum(axis=0, keepdims=True)
# Calculating the cumulative sum of elements in 'A' along axis 0 (column-wise).# 'A.cumsum(axis=0)' computes the cumulative sum column-wise.# This will result in a 3x2 tensor where each element in a column is the sum of all previous elements in that column.cumsum_result = A.cumsum(axis=0)
sum_result, cumsum_result - Dot Product
- Def.:
- Applications: Weighted sum, cosine similarity (看相似度,因為 , 最小值在 0o; 最大值在 180o → 值越接近 1 越相似,CNN 會用), projections, matrix multiplication.
x = torch.tensor([1,2,3])
y = torch.tensor([4,5,6])
torch.dot(x, y), torch.sum(x * y)
- Matrix-Vector Products
torch.mv(A, x),A @ x
- Matrix-Matrix Multiplication
A = torch.arange(6, dtype=torch.float32).reshape(3, 2)
B = torch.ones((2,3))
print(A.dtype, B.dtype)
print(torch.mm(A,B), A@B, sep="\n")
- @表 tensor 乘以 tensor,所以 vector 和 matrix 皆可使用。
- Norms (範數,即距離)
- Def.: Function that assigns a non-negative length to a vector.
- Vector Norms
- Euclidean (歐氏距離,L2 norm)
- Manhattan (曼哈頓,L1 norm)
- 推廣到 norm
- Matrix Norms: Frobenius norm
- Applications: Objective functions (目標函數), regularization (正規化), feature scaling (特徵縮放), distance metrics (距離函數), loss function.
x = torch.arange(3) #arange 預設是 int, 但 norm 要 float 才能算
print(x.dtype)
# print(torch.norm(x), torch.abs(x).sum()) # ERROR!print( torch.norm(x.to(torch.float32)) ) # Euclidean, 5**(1/2)
print( torch.abs(x.to(torch.float32)).sum() ) # element-wise abs
# Calculus
Derivatives (導數) and partial derivatives (偏導數), plays a vital role in deep learning and AI.
- Derivatives
- Def.: rate of change of f(x) with respect to x.
- Slope of the tangent to the curve of f(x) at x.
- 定義公式:
import numpy as np
def f(x):
return 3*x*x - 4*x
# Loop through values of h, starting from 10^-1 to 10^-6, decrementing by powers of 10# This loop is used to calculate the numerical approximation of the derivative of the function f at x = 1,# by applying the difference quotient formula: (f(x+h) - f(x)) / hfor h in 10.0**np.arange(-1, -6, -1):
numerical_limit = (f(1+h) - f(1)) / h
# Print the value of h and the calculated numerical limit# The output shows how the approximation of the derivative at x = 1 becomes more accurate as h gets smaller.print(f'h={h:.5f}, numerical limit={numerical_limit:.5f}')
- 常見導數和微分規則
- Constant Rule: for constant .
- Power Rule: for .
- Exponential and Logarithmic Functions: , .
- Constant Multiple Rule: .
- Sum Rule: .
- Product Rule: .
- Quotient Rule: .
- 在深度學習上的應用
- Gradient Descent: 計算損失函數相對於權重的導數。
- Backpropagation: 使用 chain rule 進行高效梯度計算。
- Model Behavior: 透過導數理解輸入輸出關係。
- Optimization: 使用導數求函數最小值 / 最大值。
- Partial Derivatives (偏微分)
- Def.: Derivative of a multivariable function with respect to one variable, treating others as constant.
- 符號: , etc.
- Gradients (梯度)
- Def.: Vector of partial derivatives for a function .
- Notation ( 念
nablaordel)
- 多變數函數的微分規則
Matrix Derivatives:- ,.
- ,.
- ,.
- .
- Frobenius Norm: .
- Chain Rule
- Application in Deep Learning
- Backpropagation: Gradient computation in neural network training.
- Gradient Descent: Weight update using computed gradients.
- Model Sensitivity: Insights into model's sensitivity to inputs.
- Single Variable: For , ,where .
- Multivariate Functions
- Vector Form: , where contains the derivatives of with respect to .
- Application in Deep Learning
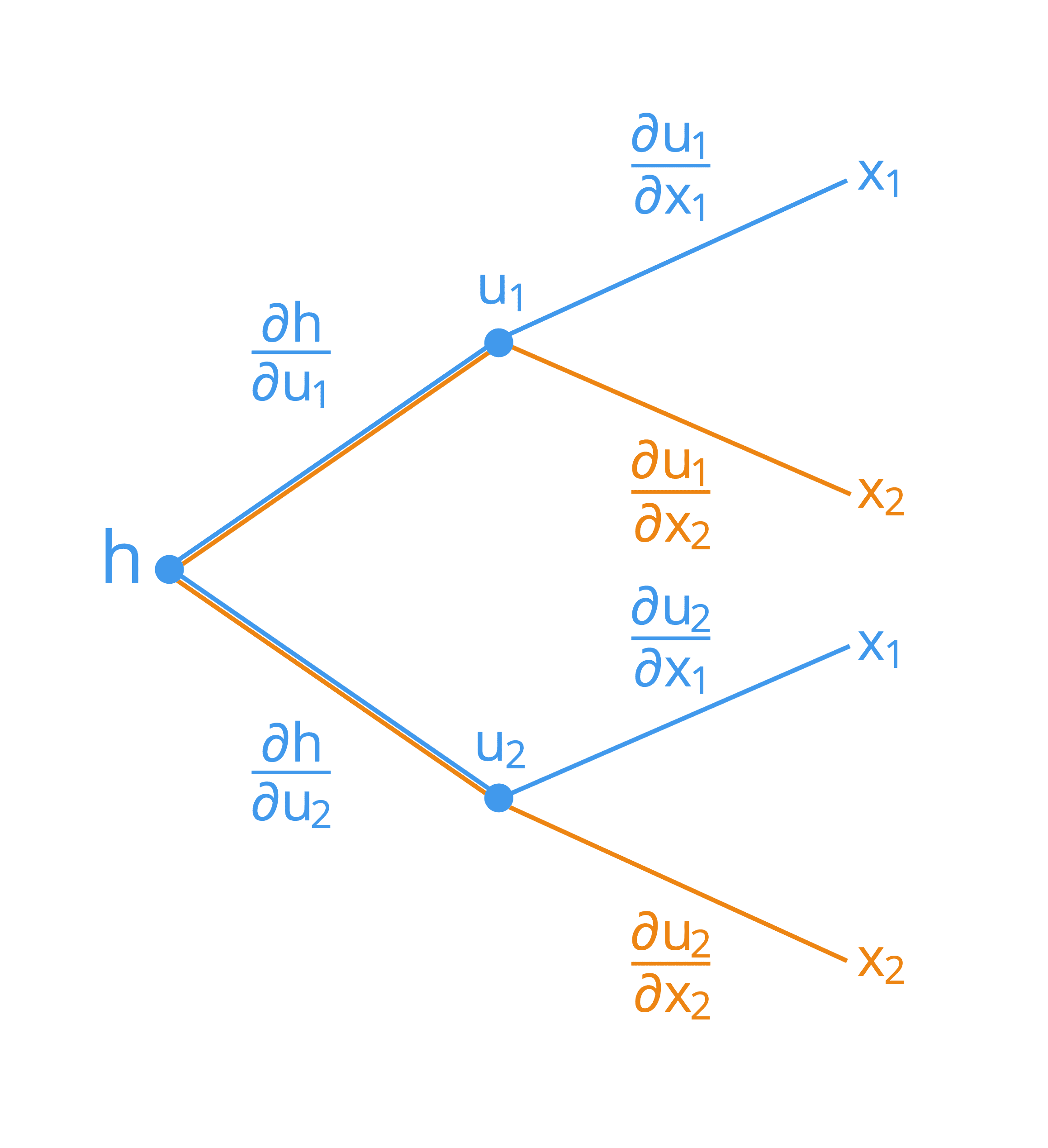
- Chain rule 圖示
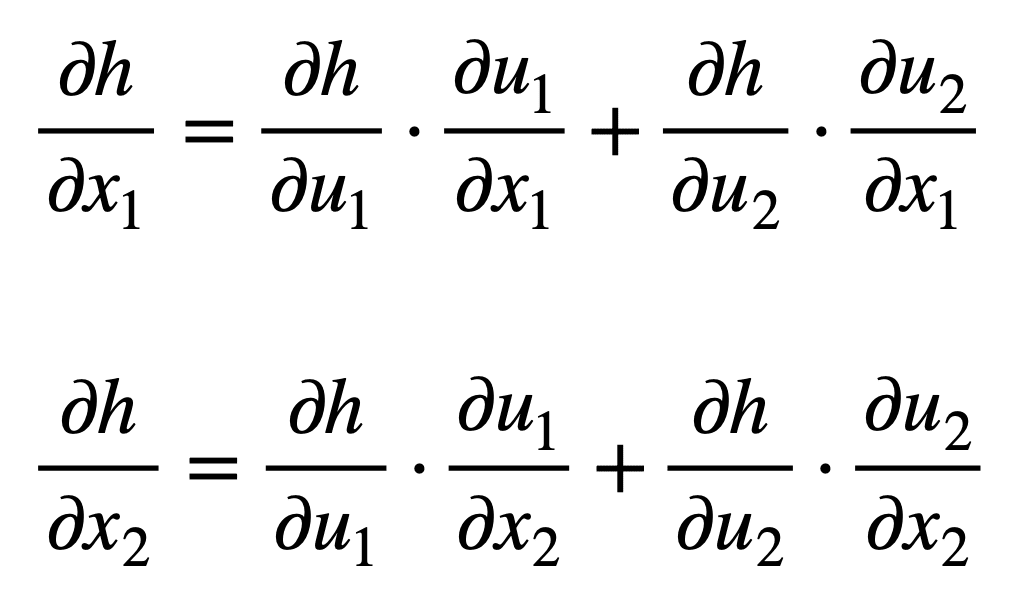 |
|---|
 |
# Auto Differentiation (自動微分)
# Bonus 2 題目
Give the function
Please implement the gradient descent method to find the local minimum of this function give the initial and .
Hint:
(1) You must use the definition to calculate the derivative of .
(2) A draft of the gradient descent method (please modify it on your own):
stop = False | |
x = x0 # initial value of x | |
alpha = 0.1 # set the learning rate to a small constant | |
t = 1 | |
while not stop: | |
f = f(x) | |
df = the derivative of f(x) at x | |
print("Iteration", t, ": f(x) = ", f, "df = ", df) # print the current function value and gradient | |
if |df|<= 1e-5: # check if the gradient is almost zero (i.e., local minimum) | |
stop = True | |
else: | |
x = x - alpha*df | |
t = t + 1 | |
print("the local minimum ", f, "is found at x = ", x) |
解答地址: Colab
ref
矩陣微分 1 https://www.youtube.com/watch?v=t8fQliDkvoE
2 https://www.youtube.com/watch?v=2Wbx4waHhcY